

Pyth Network Deep Dive : Enabling every asset price multi-chain
Pyth Network Deep Dive : Enabling every asset price multi-chain
How Pyth Network is solving the oracles problem by building a self-sustained network and building for a multichain future. Ft. LIBOR → SOFR case study

Until 2018, Blockchains had a major limitation — the DApps could only work with data already on the network. As bringing off-chain data reliably wasn’t an option, it couldn’t reliably bring off-chain data: the applications were not suitable for real-world use cases.
So, how to make blockchains communicate with the external world?
To access off-chain data, “oracles” are needed. Think of oracles as bridges to the external world!
Over the past 5 years, we have seen various types of oracles emerge from centralized to decentralized, but each of them has its own limitations. The goal of today’s project deep-dive is simple: “To make every asset price available on every blockchain”.
In this piece, we will explore the Problems that Oracles solve → Challenges faced by existing Oracles → How Pyth Solves them → Pyth’s stakeholders → Competitive Landscape & Business Model → Use-cases & the future.

Let’s go 🚀
Problems: Why do we even need Oracles?
For example, let’s suppose Raj and Stepan want to bet on the outcome of a FIFA match. Raj bets $10 on team A and Stepan bets $10 on team B, and those $20 total are now held in escrow by a smart contract, like a middleman. In a conventional world, a middleman can simply check the scores after the match ends and release the funds to the winner.
However, how would the smart contract know whether to release the funds to Raj or Stepan? A market can only read on-chain data and in this case, the match outcome is external data. This is what requires an oracle mechanism to fetch the accurate match outcomes data off-chain and deliver them to the blockchain in a secure and dependable way.
While sports is just one small use case, DeFi is a whole mammoth use case.
While you might be wondering, Oracles are unnecessary in DeFi because pricing information is frequently available on-chain. For example, querying Decentralized Exchanges(DEXs) may be used to determine to price. Compared to using an oracle, integrating the on-chain source involves no more effort in infrastructure or coordination, and the chance of a delay or off-chain failure is reduced. However, compared to centralized exchanges, DEXs sometimes have lower levels of liquidity.
As a result, DEX prices might not be indicative and are frequently simpler to manipulate than CEX prices. These problems can be solved by using an oracle since it adds reliable data from CEXs to the chain.
So, What’s exactly an Oracle?
An oracle in crypto is simply a medium that streams some data from an external source to a blockchain. So price oracles are like bridges that connect the off-chain world with the blockchain by publishing on-chain price data.
Let’s now understand the challenges faced by existing Oracles in detail👇
Challenges faced by existing Oracles:
Unreliable data sources: Some available solutions at times just scrape the data from the internet or even get that from illegal sources which makes them not accountable for the accuracy or its reliability. Most of the solutions are insufficient and unlikely to widely scale to support multiple high fidelity asset classes.
Delays: Delayed oracles can be disastrous. Let’s add some nuance to it. A great post by samczsun, “So you want to use a price oracle” touched upon some critical points around price oracles where he proposed ‘Time delays’ as a potential solution to address oracle failures.
It emphasizes the fact that because Uniswap’s oracle averages prices over a 24-hour period, short-lived price shocks are mostly ignored and even a significant and serious shock (such as 30% for an hour) will only affect the oracle price by not more than one percent, because of the averaging effect.
This Uniswap V2 TWAP (time-weighted average price) oracle can be prone to price manipulation. Because if there is too much selling pressure (for fair reasons) then the oracle will lag significantly from the “accurate” or “true” price and will show a stale price across all protocols where it is being used. Though this might not be an issue for stable assets where the volatility is fairly low, but crypto, as we know is a tale of spikes and dips, so being this volatile the problem of TWAP becomes even worse. Even in real-life scenarios like this using a twenty-minute TWAP can lead to a huge lag in the oracle price as compared to a Centralized Exchange like Binance, or FTX.
Though the motivation for introducing delays seems to stop the market exploits in DeFi, whereas for markets with high volume and volatility, it might not work the best.
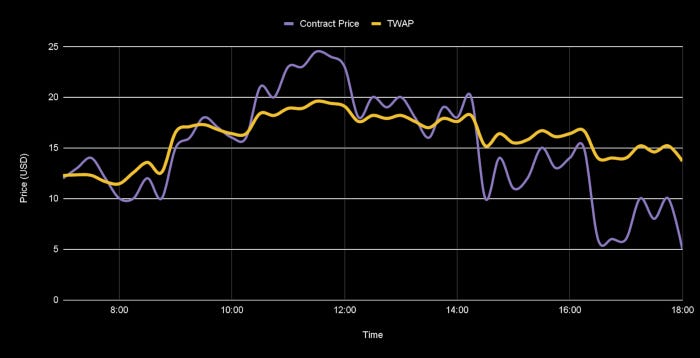
Now think about using oracles with TWAPs in real-time financial products with such latency. It will be a disaster! DEXs will show not show correct prices and arbitragers might take advantage of some protocols to make some profits.

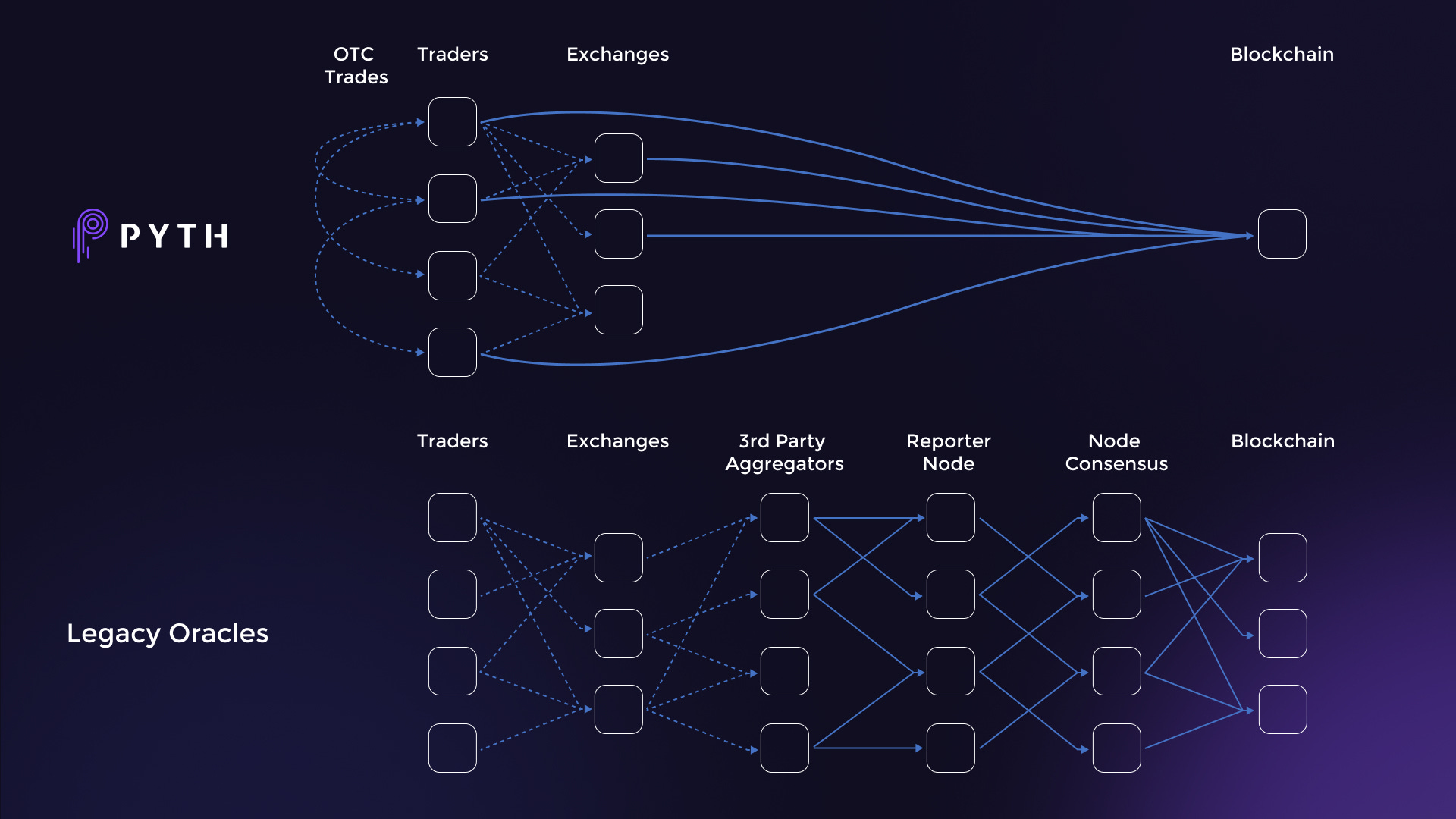
Let’s now look at an interesting case study of LIBOR by Jump👇
LIBOR → SOFR Case Study
Aligned incentives are necessary for a low-latency product like a financial oracle. When we talk about incentive alignment, there is one story that tells an interesting story with a lesson and solution. It’s about LIBOR (London Interbank Bank Offered Rate).
The (theoretical) rate at which the biggest banks may exchange short-term unsecured loans with one another as indicated by LIBOR. Simply put, it’s the exchange rate between banks. In this, about 16 prominent banks with operations in London were surveyed every day before 11:30 am GMT. Considering currencies and maturities, the following question was posed to them: “If you were to look for and accept interbank offers in a fair market size just before 11 am, at what rate might you borrow money?” The findings experienced modest editing where the top and bottom four replies would be eliminated to remove variations. At 11:30 GMT, the averages of the remaining submissions were released as the day’s LIBOR benchmark. These responses were anonymous
Soon it started to be seen as the epicenter of finance and the rate got used for more than $300 Trillion notional in contracts like loans, and mortgages to complex instruments like futures.
But it wasn’t too late until some banks started to misreport the LIBOR submission and started gaming it to rake in more profits. This finally ended the rate’s dominance in 2021 (which has been there for 52 long years) and resulted in penalties and criminal prosecution.
In this context, if we consider staking, then we start to connect the dots around the fundamental design challenges to LIBOR:
Participants did not stake any collateral on the accuracy of the information, leading to misreporting of rates.
Participants were reporting rates on hypothetical scenarios and not based on their trades.
Participants lacked skin in the game as they were collectively anonymous, which lowered their reputational risk if they manipulate the rates.
SOFR fixes this!
Secured Overnight Financing Rate (SOFR) solves these design challenges, as it is based on real transaction data and not hypothetical data and uses a “Staking by Trading mechanism”. SOFR is calculated directly by the Federal Reserve Bank of New York. This strong supervision and regulatory powers, make it harder to manipulate making it a strong reputational staking mechanism.
How Pyth solves them?
Pyth network is an oracle solution, which makes timely, accurate, and valuable financial market data accessible on the blockchain with an interesting incentive model and protocol design.
Let’s go a bit further.
Both on-chain and off-chain apps can utilize the first-party chain price data that is gathered by the Pyth network. It is able to achieve this by offering incentives for market participants, including market makers, exchanges, and trading firms, to provide on-chain price data as a part of their regular business operations.
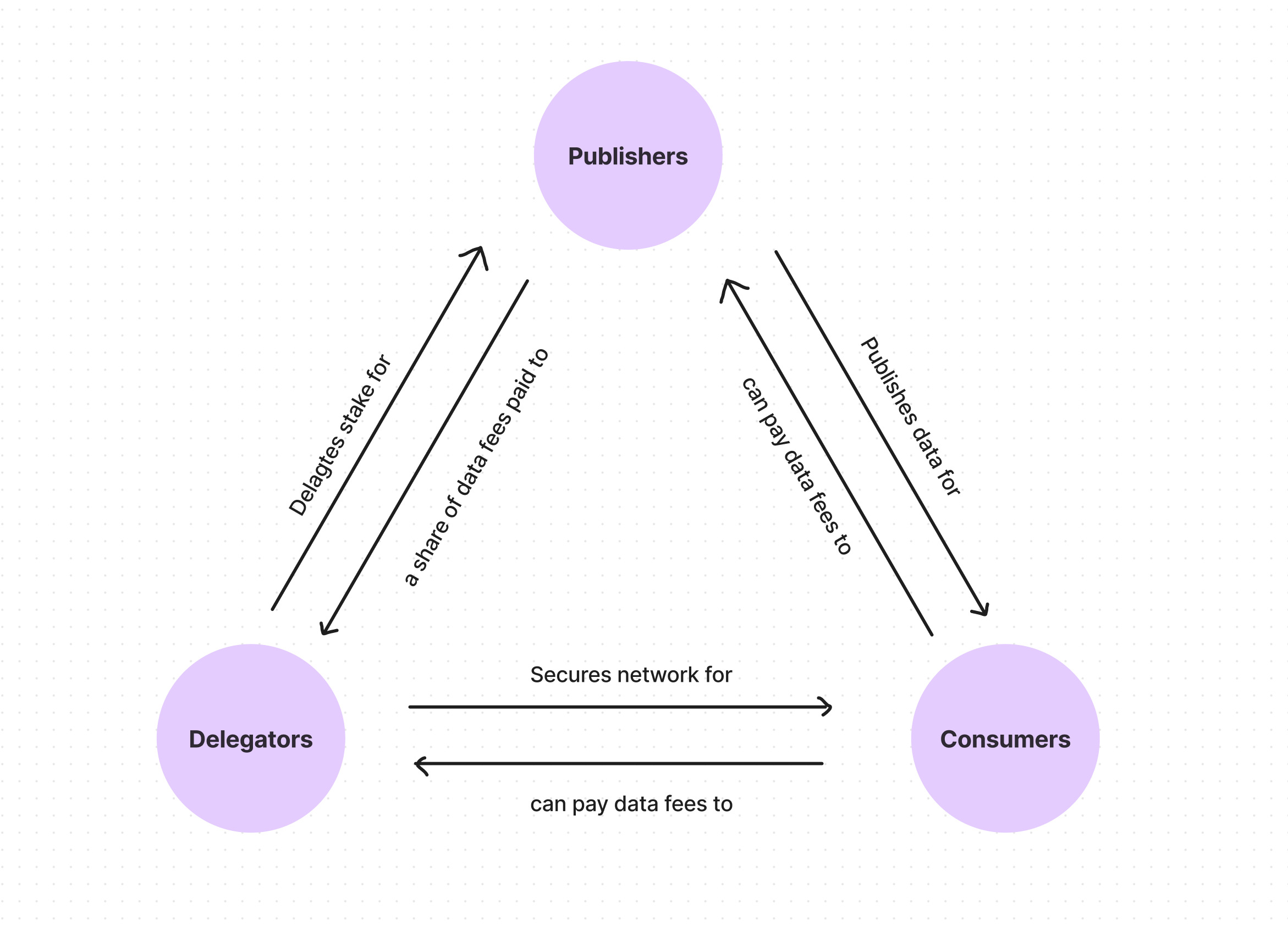
So here the data publishers have to stake tokens in order to publish data for a product and if they publish price data that has some error or is mistaken then their stake is given out to the end users (consumers) who pay data fees.
Delegators on the other hand choose which price feed to stake on top of so that they earn data fees with the risk of potentially losing their stake if the oracle is inaccurate due to the publishers’ fault. Though at first 80% of the data fees will go towards paying delegators and the publishers will share the remaining 20% (these parameters are subjected to PYTH’s governance)
Building a self-sustained and decentralized network
The network consists of 3 parties
Publishers
Publishers have the access to accurate and timely price data, they publish those price feeds and earn a share of data fees.
They need to stake PYTH tokens to participate in the protocol and earn a % of the rewards (data fees). Here staking makes the publishers to have some skin in the game, which means if they provide incorrect or inaccurate data (whether intentionally or not) their stake will get slashed.
2. Consumers
Consumers read those price data and use that in their dApps by incorporating that data into their smart contracts. Consumers can be both on-chain or off-chain applicants who will pay the data fees.
They pay data fees mostly for two reasons:
First and the most important reason is that using Pyth price feeds will reduce their risk, as they can receive a payout if there is a failure.
The other reason simply is, by paying data fees, more publishers use the product, increasing the reliability of the price feed.
3. Delegators
Delegators can stake tokens on a particular publisher to receive a percentage of the data fees generated (paid by consumers), but there is a risk that they could possibly lose their stake if the oracle proves to be incorrect.
Though delegators will initially receive lucrative payouts, but as the market grows more efficient and there is greater competition among them, the payments might eventually decline.
Traction
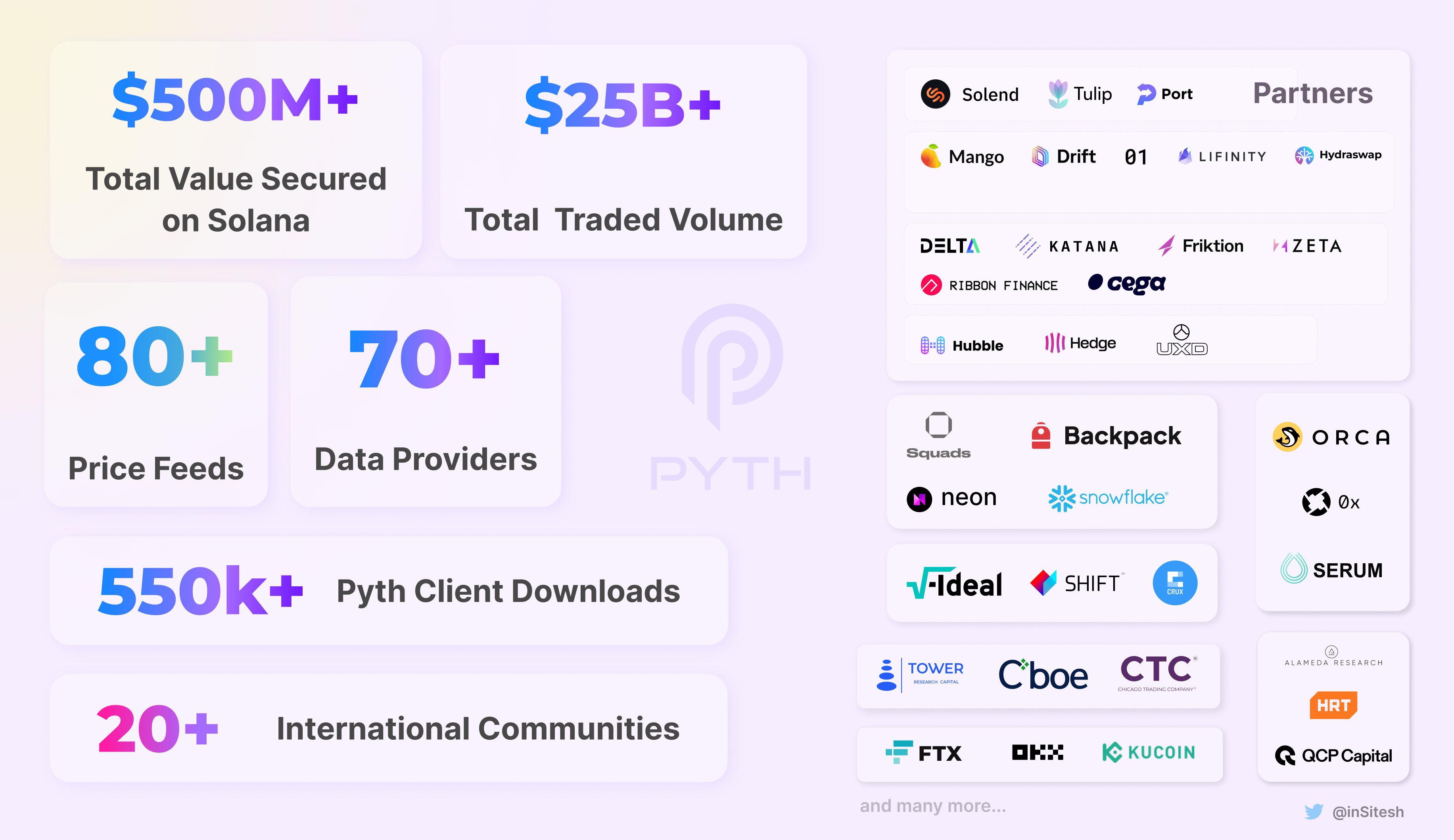
Pyth launched on Solana mainnet in August 2021, after launching on devnet in April 2021. In just over a year, it has secured over 90% TVS (Total Value Secured) of Solana’s Addressable Market, 550K+ client downloads, and half a billion value secured.
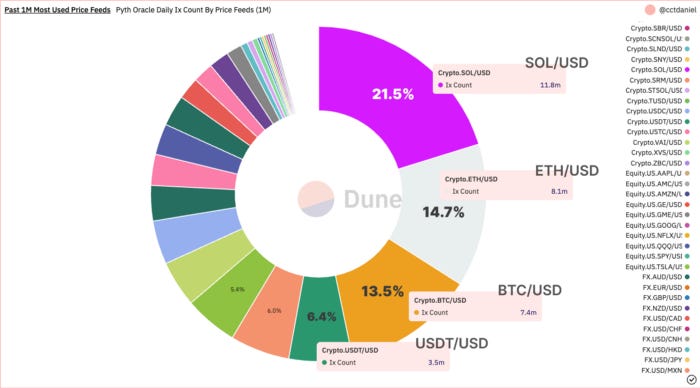
Today, there are 70+ publishers supporting the network, and more than 80 price feeds are supported. The most used price feeds are SOL/USD (21.5%), ETH/USD (14.7%), and BTC/USD (13.5%) followed by all other cryptos/USD pairs.
Pyth has two types of clients: Data Consumers & Data Publishers
Clients [Data Consumers]
Over 72 Protocols & Projects, now use Pyth as the price feeds provider. Their data consumers include a wide range of categories:
1. DeFi: Asset prices are the obvious use case here.
a. Lending & Borrowing: They generally use Pyth’s oracle prices and confidence to actively track their users’ account health and to determine liquidations.
Examples: Solend, Tulip, Port Finance
b. DEXs & AMMs: These utilize Pyth’s real-time prices to make sure they are in sync with other exchanges.
Examples: Mango Markets, Drift, 01, Lifinity, DeltaFi, HydraSwap
c. Options & Derivatives, Structured Products, and Vaults: They leverage Pyth’s price feeds for options settlement at expiry and compare with the strike price to determine the P&L of their vaults/structured products.
Examples: Zeta Markets, Ribbon Finance, Friktion, Katana, Cega
d. Stablecoins: Since these stablecoins are backed by either collateral assets like SRM or RAY or using derivatives to remain stable, all these price feeds are fed by Pyth Oracles!
Examples: Hubble, Hedge, UXD
2. DAO tooling & Infra.
All the tooling & infra projects require asset prices for interacting across chains, multi-sigs, etc.
Examples: Squads, Snowflake, Neon EVM, Backpack
3. Off-chain Applications:
These are ideally analytics platforms that require various asset price data for analytics purposes.
Examples: SHIFT Search, Crux, Ideal Prediction

The most active consumers by the number of transactions are DEXs & Derivative platforms like Zeta, Mango, Entropy, and 01. You can check out the entire list of consumers here
Clients [Data Publishers]
The Data publishers act as suppliers of data, which is a critical piece of the data flow. Over 77 data publishers now publish data in the Pyth network. The current publishers comprise:
Market makers & Trading Firms like Alameda Research, Hudson River Trading, QCP Capital
Traditional exchanges like CBOE Global Markets, Chicago Trading Company
Crypto exchanges like FTX, OKX, KuCoin
Decentralized exchanges like Orca, 0x, Serum

You can check out the entire list of publishers here.
Business Model & PYTH Token Model:
Pyth currently generates ~65 SOL as fees, and monthly fees amount to ~1750 SOL. By this calculation, we get an Annual Revenue of $700K as per the current SOL Price. However, if we have a bull market, the annual revenue can even shoot up to $10–20M, given the high volume of transactions and higher SOL price.
Pyth Network will be soon releasing its own native token — PYTH, which will enable:
Publishers to stake PYTH and earn a share of data fees
Consumers can pay PYTH as data fees
Delegators will stake PYTH on specific price feeds to earn a share of data fees.
In case of any misbehavior like incorrect data, the staked PYTH will be used to compensate the consumers.
Overall, Incorporating these tokenomics will significantly improve Pyth’s current business model, as now instead of using SOL, they can leverage their own native token as a currency for using Pyth.
Competitive Landscape: Threats & Opportunities
While Pyth is a dominant player on Solana (>90% market share), Switchboard is another emerging player on Solana. However, Pyth has developed a serious moat in Solana due to the following reasons:
Highest quality Institutional-grade data from first-party sources, who actively participate in price discovery.
No other oracle solution updates with as much frequency as Pyth protects users with high confidence intervals & ensures high oracle reliability, transparency, and data legality.
Apart from these, players like ChainLink have been there for quite a long time in Ethereum Ecosystem, and pose a serious threat to Pyth in the multi-chain future. In comparison, ChainLink has 1000+ data consumers, with 12+ Blockchains supported and a $75 Billion Total Value Secured at its peak in December 2021, with a cumulative transaction value enabled of $6 Trillion+
Building for the multi-chain future 🔮
Pyth is now live on the mainnet on BNB Chain with Venus as the early adopter. It has also launched on Aptos, and the protocols on Aptos like Aries Market can even access price feeds like APTOS/USD apart from the normal price feeds. The next blockchains in the line are L1s and L2s, including Ethereum, Polygon, Injective, NEAR, Avalanche, Fantom, Algorand, Arbitrum, Optimism, Sui, and more.
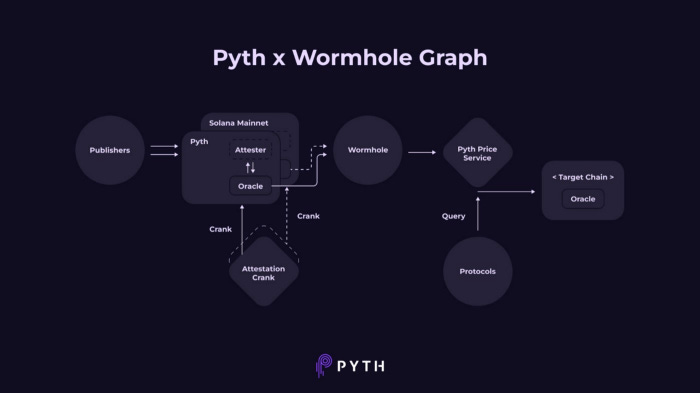
How does it take the data Cross-chain?
The publishers will continue sending the pricing data to the on-chain program as usual. However, in order to send it to other blockchains, Pyth will be leveraging Wormhole’s generic messaging protocol. Simply put, Wormhole is a bridge that allows the flow of information or tokens from one blockchain like Ethereum to another blockchain like Solana.
For instance, A data consumer from a wormhole-supported chain like Binance Smart Chain would be able to request Pyth prices from Wormhole. Once the request is received, the wormhole will vouch for the prices from Pyth and transfer those prices to the Pyth contract deployed on Binance Smart Chain i.e the user’s native chain. This implies that any protocol from that chain can request prices at their desired frequency from the relevant Pyth contract.
The prices will be available on-demand to ensure cost reductions and once a particular data is requested, everyone else on that chain can use those data.
“If it’s fair game for Wormhole, it’s fair game for Pyth.”
After all, Both Wormhole & Pyth are pet projects of Jump Crypto, after all — we love Jump :)
Future Use-Cases and Applications for Pyth 🧪
Right now, the data feeds are dominated by Crypto-USD pairs, however, as we take more and more applications & financial assets on-chain, the need for reliable external data will only increase exponentially. A few use cases that would present huge opportunities for Pyth might be:
Real-World Assets on-chain: With more and more real-world assets like Trade Finance, Revenue-based Finance, Carbon Credits, and Real Estate coming on-chain, there will be an immense need for reliable data for these external assets. For instance, if someone wants Real Estate in New York to be tradable on-chain, they would need a price oracle for Real Estate, through which they can obtain reliable & robust prices.
Weather, Politics & Sports: With Pyth focussing primarily on “Financial Markets” data right now, there lies a ton of opportunity to build for non-financial sectors like Weather, Sports, or even Politics. An obvious use case here is prediction markets, where smart contracts require reliable data sources for settling bets related to topics like Sports. Finding reliable data publishers would be key here.
Conclusion: Can Pyth be a Trillion dollar in Value Secured Project?
Pyth has made significant progress toward bringing reliable & valuable 80+ financial data like Crypto, Equities, and Commodities sub-second price updates to Solana. However, in terms of price feeds, it hasn’t even scratched the surface, there are thousands of data lying around, which are yet to be published on-chain. Besides, bringing a diverse range of data, expanding multi-chain, and moving towards self-sustaining and completely decentralized is the ultimate goal.
However, the path is not easy — we saw this in the recent Mango Markets fiasco, where Pyth’s price feed wasn’t even used, but such Price Oracle manipulations do pose a threat. Going cross-chain would also come up with its own opportunities and threats. If they are able to successfully, tap other chains, they can easily secure $1 Trillion as the value in the next 2–3 years.
It’s still early days for Pyth, and the team behind Pyth (Jump Crypto) is A+ which will ensure the robustness of the network, which also presents a strong bull case for the Pyth network. If executed correctly, then the end crypto consumers can harness the power of DeFi coupled with the speed and reliability of traditional markets.🚀
That’s all folks!
— Thanks to Yash Agarwal for helping with key concepts and reviewing this article.
.
.This was a deep dive into the Pyth Network and how it is solving for the backbone of the numbers we see and movements we experience in dApps. If you find it helpful or want to suggest anything feel free to reach out to me at @inSitesh on Twitter.
Until then…
Sources:
DO YOUR OWN RESEARCH. We make no representation or warranty as to the accuracy or completeness of the information contained in this report, including third-party data sources. This post may contain forward-looking statements or projections based on our current beliefs and information believed to be reasonable at the time. However, such statements necessarily involve risk and uncertainty and should not be used as the basis for investment decisions. The views expressed are as of the publication date and are subject to change at any time. Read the full disclaimer here.